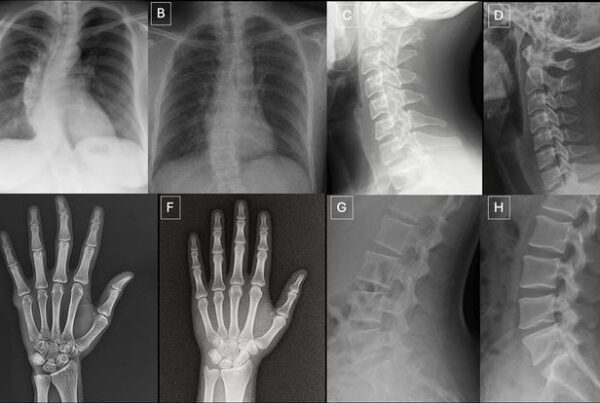
O Desafio de Inteligência Artificial da Sociedade Paulista de Radiologia e Diagnóstico por Imagem (SPR) que acontece durante a JPR 2023 está despertando o interesse de muitos profissionais da saúde e cientistas de dados em todo o mundo. Nesse desafio, os participantes devem criar modelos capazes de prever o gênero e a faixa etária de um paciente a partir de radiografias de tórax. O resultado do desafio será divulgado na 53ª Jornada Paulista de Radiologia e tem como apoiador a Amazon Web Services
Neste post, vamos mostrar como é possível participar do desafio mesmo sem ser um programador. Vamos explicar como o Google Teachable Machine pode ser usado para treinar a inteligência artificial (IA) e como a plataforma Kaggle pode ser utilizada para submeter os modelos criados.
Como participar no Desafio de Inteligência Artificial da SPR?
Para participar no Desafio de Inteligência Artificial da SPR na JPR 2023, os interessados devem acessar a plataforma Kaggle e se inscrever no desafio de sua escolha: SPR X-Ray Gender Prediction Challenge ou SPR X-Ray Age Prediction Challenge.
Em seguida, será necessário baixar o conjunto de dados que será utilizado no desafio e começar a desenvolver um modelo de inteligência artificial capaz de prever o gênero e/ou a faixa etária de um paciente a partir de radiografias de tórax.
Mas afinal o que é Kaggle?
A plataforma Kaggle é uma comunidade online de cientistas de dados que se dedica a resolver desafios complexos utilizando técnicas avançadas de aprendizado de máquina e inteligência artificial. O Kaggle oferece uma série de desafios e competições de dados, incluindo o Desafio de Inteligência Artificial da SPR e os desafios promovidos pela RSNA: Radiological Society of North America
Para se inscrever no Kaggle é bem simples, ao acessar o site, clique no botão “Register” no canto superior direito da página conforme ilustra a figura abaixo.
Plataforma Kaggle
Depois basta selecionar a opção para entrar com sua conta Google ou criar uma conta a partir de seu email

Registrando uma conta no Kaggle
Os participantes do desafio podem utilizar o Kaggle para baixar os dados que serão utilizados para treinar os modelos de inteligência artificial, bem como para submeter suas soluções. Além disso, a plataforma oferece recursos para ajudar os participantes a melhorar seus modelos e obter melhores resultados. Você poderá ainda ver os scripts disponibilizados pelos outros participantes para treinamento da IA, isso é muito útil para quem está buscando aprender a como utilizar a linguagem de programação python no desenvolvimento de softwares para treinar sua própria IA. O exemplos disponibilizados pelo usuário LEONARDO ALMEIDA para o desafio de idade e para o desafio de gênero , são um ótimo ponto de partida para quem está iniciando no mundo da programação.
Como usar o Google Teachable Machine para treinar a IA?
Agora que você entendeu como funcionará o Desafio de Inteligência Artificial da SPR na JPR 2023 e como ele está relacionado à predição de idade e gênero a partir de radiografias de tórax, vamos falar sobre como usar o Google Teachable Machine para treinar a Inteligência Artificial.
O que é Google Teachable Machine?
O Google Teachable Machine é uma ferramenta gratuita e fácil de usar que permite treinar modelos de aprendizado de máquina sem a necessidade de programação. Isso significa que mesmo se você não tem conhecimento prévio em programação, pode participar do desafio da SPR na JPR 2023 usando essa plataforma e pode treinar seus próprios modelos de inteligência artificial. A plataforma usa técnicas de aprendizado de máquina supervisionado, que é quando uma rede neural é alimentada com exemplos para aprender a fazer uma determinada tarefa.
Como funciona o Google Teachable Machine?
O funcionamento do Google Teachable Machine é relativamente simples. A plataforma permite que o usuário crie modelos de IA com classes diferentes, que podem ser treinadas com imagens, sons ou gestos. As classes são os rótulos que a IA irá aprender a identificar, como por exemplo, “feminino”, “masculino” em uma classificação de imagens e fornecer as imagens de exemplo para o sistema.
Para treinar um modelo de IA no Google Teachable Machine, basta seguir três passos simples: coletar dados, treinar o modelo e testar o modelo. Na etapa de coletar dados, o usuário precisa fornecer exemplos para cada uma das classes que deseja treinar. Por exemplo, se o objetivo é treinar uma IA para identificar o gênero masculino e feminino em imagens de raios-x de tórax, o usuário precisa coletar imagens de raios-x de tórax femininos e masculinos para ensinar o modelo a distinguir entre elas.
Na etapa de treinar o modelo, o Google Teachable Machine usa algoritmos de aprendizado de máquina para criar um modelo que possa identificar as classes fornecidas pelo usuário. A plataforma apresenta um feedback em tempo real do desempenho do modelo durante o treinamento, o que permite ao usuário ajustar os dados de entrada para melhorar a precisão do modelo.
Na etapa final de testar o modelo, o usuário pode avaliar a precisão do modelo ao fornecer novos exemplos que não foram usados no treinamento. Isso é importante para garantir que o modelo possa generalizar o conhecimento e identificar corretamente as classes.
Como treinar uma IA para identificar o gênero em imagens de raios-x de torax usando o Google Teachable Machine?
Treinar uma IA usando o Google Teachable Machine é uma tarefa relativamente simples. No entanto, é importante seguir algumas boas práticas para garantir que o modelo seja preciso e eficiente.
Coletar exemplos de alta qualidade:
Os exemplos fornecidos para cada classe devem ser de alta qualidade e variados, para que o modelo possa identificar corretamente as características de cada classe. Certifique-se de ter exemplos suficientes para cada classe, para que o modelo possa aprender corretamente.
Etiquetar os exemplos:
O próximo passo é etiquetar cada exemplo de acordo com sua classe correspondente. Por exemplo, se você estiver treinando uma IA para identificar diferentes espécies de flores, é necessário etiquetar cada imagem com o nome da espécie correspondente. No nosso caso podemos separa em dois gêneros “Masculino” e “Feminino”, ou para idade ”
Treinar o modelo:
Após a etiquetagem, é hora de treinar o modelo. O Google Teachable Machine oferece diferentes opções de treinamento, como treinamento rápido, médio e lento, dependendo do tamanho do conjunto de dados. É importante escolher a opção que melhor se adapta às suas necessidades e recursos disponíveis.
Testar o modelo:
Após o treinamento, é importante testar o modelo para verificar sua precisão. Para isso, é necessário fornecer exemplos que o modelo não viu antes e verificar se ele consegue identificar corretamente a classe correspondente. Se necessário, é possível ajustar o modelo e repetir o processo de treinamento e teste até que se obtenha um modelo preciso.
Exportar o modelo:
Após o treinamento e teste, é possível exportar o modelo em diferentes formatos, como TensorFlow.js, TensorFlow Lite e Arduino, para que possa ser integrado em diferentes plataformas e dispositivos.
Atenção, os estudos de imagem usados no desafio da SPR foram fornecidos por várias fontes e são dados de pacientes não identificados, o que significa que as instituições contribuintes tomaram cuidado razoável para remover todas as informações de identificação pessoal. Como participante da Competição, você concorda em:
1) não fazer cópias ou redistribuir de qualquer forma, nenhum dos dados disponibilizados a você,
2) não tentar reidentificar qualquer informação pessoal com base nos dados,
3 ) não tentar probing do ground truth do conjunto de teste e
4) notificar os organizadores da Competição sobre qualquer informação de identificação pessoal que você encontrar nos dados enviando um e-mail para desafio.ia@spr.org.br.
Como treinar uma IA com as imagens DICOM do meu setor de radiologia?
Treinar uma IA com imagens DICOM do setor de radiologia usando o Google Teachable Machine pode ser uma excelente maneira testar o poder da IA. No entanto, é importante seguir algumas etapas para garantir que seu modelo seja preciso e confiável.
A primeira etapa é exportar as imagens DICOM do PACS em formato JPEG ou PNG. Em seguida, é necessário etiquetar os exemplos e classificá-los em suas respectivas classes, como por exemplo gênero e idade. Certifique-se de ter um número suficiente de exemplos para cada classe e de que nenhuma classe tenha mais exemplos do que as outras. Será necessário separar as imagens de treino das imagens de teste para cada classe.
Após etiquetar os exemplos, é hora de treinar o modelo. O Google Teachable Machine usa um algoritmo de aprendizado profundo chamado Convolutional Neural Network (CNN) para treinar modelos de reconhecimento de imagens. O processo de treinamento envolve alimentar o modelo com os exemplos coletados e ajustar os pesos das conexões neurais para maximizar a precisão do modelo.
Agorá e só testar a sua IA utilizando as imagens de teste que você separou e exportar os resultados.
Bases de dados gratuitas de imagens DICOM para treinamento de IA
Se você quiser treinar sua IA utilizando bases de dados gratuitas, abaixo listamos algumas bases de dados gratuitas de imagens DICOM que podem ser usadas para treinar modelos de IA em radiologia:
- The Cancer Imaging Archive (TCIA): o TCIA é um repositório público de imagens médicas, incluindo imagens DICOM, para fins de pesquisa e ensino. A plataforma é mantida pelo National Cancer Institute (NCI) dos EUA e contém uma ampla variedade de conjuntos de dados, incluindo radioterapia.
- Radiopaedia: O Radiopaedia é um site colaborativo de radiologia que permite que radiologistas compartilhem casos e imagens de radiologia de todo o mundo. A plataforma contém um grande número de imagens DICOM de alta qualidade que podem ser usadas para treinar modelos de IA em radiologia.
- OpenI: o OpenI é uma plataforma de busca de imagens médicas mantida pelos Institutos Nacionais de Saúde dos EUA. O OpenI contém imagens de várias modalidades, incluindo imagens DICOM, e pode ser usado para treinar modelos de IA em radiologia.
- RSNA Radiology: A Sociedade Radiológica da América do Norte (RSNA) mantém um repositório de imagens radiológicas para fins de ensino e pesquisa. O repositório contém uma grande variedade de imagens DICOM e pode ser usado para treinar modelos de IA em radiologia.
- NIH Clinical Center: O Centro Clínico Nacional dos Institutos Nacionais de Saúde dos EUA mantém um banco de dados de imagens médicas, incluindo imagens DICOM, para fins de pesquisa e ensino. O banco de dados contém imagens de várias modalidades, incluindo radiologia, e pode ser usado para treinar modelos de IA em radiologia.
- Medseg Lista de base de dados no link
Conclusão
O ganhador do desafio de Inteligência Artificial da SPR será divulgado na JPR 2023. Este desafio é uma oportunidade única para que profissionais de saúde iniciem seus estudos sobre inteligência artificial. Não deixe de participar!