Existe una forma muy eficaz de producir confusión en física clínica: volver a calcular el mismo caso en dos motores, abrir DVHs uno al lado del otro y tratar cualquier diferencia como evidencia. En casi todos los servicios nacen así frases como “el algoritmo X calcula más dosis” o “el algoritmo Y es más conservador”. La comparación casi nunca es lo suficientemente clara como para respaldar esto.
La razón es simple. Cuando dos resultados difieren, lo que se compara no es sólo el nombre del motor. Por lo general, incluyen beam model, resolución de cuadrícula, mapeo de materiales, convención de dosis, parámetros MLC e incluso el alcance de validación de esa técnica en la máquina real.
Por eso esta parte del clúster es tan rutinaria. Comprenda AAA, Acuros XB, collapsed cone y Monte Carlo es importante. Saber comparar estos motores sin cometer errores con la propia metodología es lo que realmente cambia la práctica.
En este artículo
- 1. El primer error: pensar que el algoritmo es igual al resultado
- 2. Modelo de vigas: la parte invisible de la comparación
- 3. El segundo error: comparar diferentes grillas como si fueran la misma cosa
- 4. El tercer error: ignorar la convención de dosis
- 5. El cuarto error: tratar la técnica como si estuviera validada automáticamente
- 6. Qué debería responder realmente la puesta en servicio
- 7. Una matriz de pruebas es mejor que un montón de mediciones desconectadas
- 8. El papel de los fantasmas heterogéneos
- 9. Gamma no resuelve todo
- 10. El QA por paciente no reemplaza el QA del algoritmo
- 11. Cuando comparar algoritmos es realmente útil
- 12. Una hoja de ruta mínima para comparar rigurosamente algoritmos
- 13. Lo que la literatura y los manuales enseñan juntos
- 14. El verdadero beneficio de una comparación bien hecha
El primer error: pensar que el algoritmo es igual al resultado
El algoritmo importa mucho, pero nunca funciona solo. En cualquier comercial serio TPS, el resultado que aparece en la pantalla depende de al menos cinco capas:
- modelo de haz (beam model);
- datos de puesta en marcha y medición;
- resolución y discretización;
- representación del paciente y materiales;
- convención de notificación de dosis.
Cuando alguien dice que “el algoritmo X dio una dosis mayor que el algoritmo Y”, la oración está incompleta. Lo que proporcionaba la mayor dosis era todo un conjunto de opciones: motor, modelo, parrilla, mapeo de materiales, técnica, máquina y, a veces, diferente magnitud de dosis.
Modelo de vigas: la parte invisible de la comparación
beam model es uno de los factores más subestimados en las comparaciones TPS. Define cómo el sistema describe:
- la fuente primaria;
- fotones extrafocales;
- contaminación electrónica;
- colimadores;
- MLC;
- cuñas;
- factores de producción;
- parámetros geométricos y dosimétricos de la viga.
Eclipse deja esto claro al mostrar que AAA y Acuros XB comparten el mismo modelo de fuente de haz de fotones . RayStation insiste, en sus IFU, que ciertos escenarios, especialmente planes de rotación de campos pequeños, son altamente sensibles a los parámetros MLC de beam model.
Esta observación es decisiva. A veces el físico cree que está viendo una diferencia en la familia algorítmica, cuando en realidad está viendo:
- diferencia en MLC modelado;
- diferencia de puesta en marcha;
- diferencia de parametrización de fuente.
Sin aislar estas capas, la comparación se convierte en una mezcla de causas.
El segundo error: comparar diferentes grillas como si fueran la misma cosa
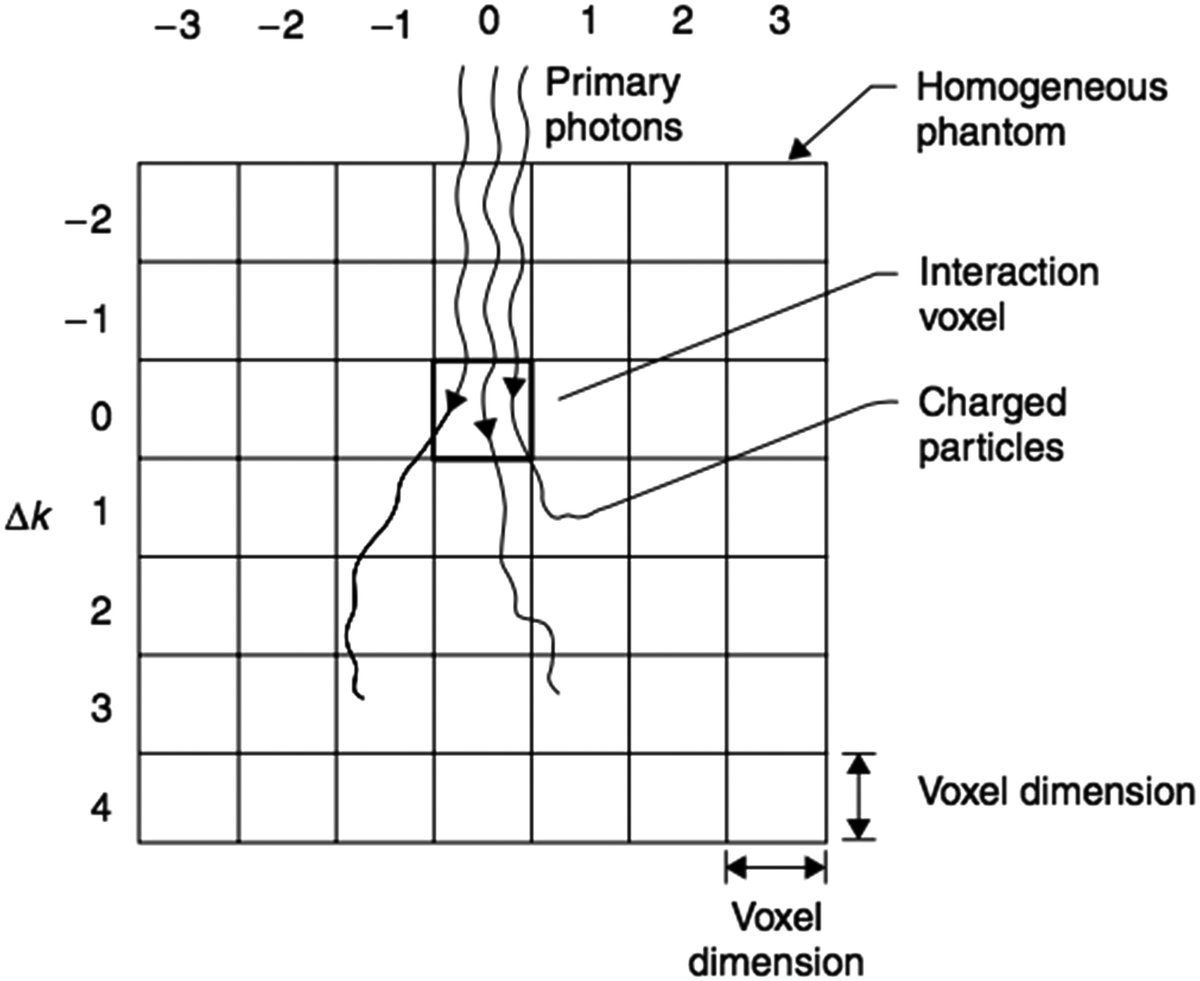
La resolución de dosis no es un detalle cosmético. Cambia:
- muestreo de gradiente;
- definición de penumbra;
- dosis en pequeños volúmenes;
- comportamiento en interfaces;
- apariencia de concordancia entre algoritmos.
AAA utiliza una cuadrícula divergente internamente y depende de la relación de resolución elegida. espaciado de píxeles y separación entre cortes. Acuros XB utiliza discretización espacial variable con refinamiento adaptativo. Monte Carlo, a su vez, también trae el componente adicional de ruido estadístico por vóxel.
Esto significa que comparar dos algoritmos sin ecualizar la malla de salida, o sin al menos entender cómo cada uno discretiza el problema internamente, es metodológicamente frágil.
Una regla general útil es la siguiente: antes de hablar de física, alinee la discretización.
El tercer error: ignorar la convención de dosis
Este punto se vuelve cada vez más importante a medida que los servicios comienzan a utilizar algoritmos explícitos en el material.
Acuros XB permite dose to medium y dose to water. EL RayStation, en el material local, advierte que el fotón collapsed cone calcula la dosis para el agua, mientras que el fotón Monte Carlo informa la dosis para el medio. El mismo documento advierte explícitamente sobre el riesgo de combinar o comparar diferentes distribuciones de motores cuando el caso es sensible a materiales con alto Z.
Si el servicio ignora esto, lo que parece una divergencia algorítmica puede ser, en parte, una divergencia de cantidades físicas informada.
En términos prácticos, antes de comparar cualquier dosis entre motores, el físico debe responder:
- ¿los dos motores informan la misma convención?
- ¿Es pequeña la diferencia esperada entre convenciones en este material?
- ¿Existe hueso, implante u otro material que amplifique esta discrepancia?
Sin estas preguntas, incluso un bonito DVH podría malinterpretarse.
El cuarto error: tratar la técnica como si estuviera validada automáticamente
IFU por RayStation es muy útil porque habla el lenguaje que todo servicio debería adoptar. El documento nos recuerda que ciertas técnicas, como VMAT secuenciación, deben tratarse como prácticamente una técnica nueva, que requiere:
- validación de beam model;
- validación del comportamiento de la máquina;
- Control de calidad por paciente.
Esta observación debería universalizarse. El hecho de que un algoritmo funcione muy bien en 3D-CRT no garantiza automáticamente el mismo comportamiento en:
- IMRT fijo;
- VMAT;
- arcos de ondas;
- campos demasiado pequeños;
- técnicas específicas de la plataforma.
Siempre que cambia la técnica, es necesario reevaluar la validez del conjunto algoritmo + beam model + entrega .
Qué debería responder realmente la puesta en servicio
En lugar de tratar la puesta en servicio como una lista de verificación genérica, vale la pena hacer las preguntas correctas.
Una puesta en servicio seria debe mostrar:
- si el motor reproduce la profundidad de dosis, los perfiles y los factores de salida de la máquina;
- si el comportamiento se mantiene en campos pequeños;
- si el algoritmo responde correctamente en medios heterogéneos relevantes para la clínica local;
- si el modelado de MLC es adecuado;
- si las opciones de cuadrícula e imagen no introducen artefactos relevantes;
- si la convención de dosis adoptada es conocida y consistente.
En otras palabras, poner en marcha no es “hacer pasar el algoritmo”. Se trata de descubrir en qué territorio se puede utilizar ese conjunto con confianza.
Una matriz de pruebas es mejor que un montón de mediciones desconectadas
En lugar de pensar en la puesta en servicio como una recopilación de datos, vale la pena pensar en ella como una matriz de preguntas. Una matriz mínima útil suele cruzar:
- campo abierto y campo pequeño;
- homogéneos y heterogéneos;
- eje central y fuera del eje;
- técnica simple y técnica modulada;
- material equivalente al agua y material clínicamente desafiante.
Cuando el equipo elabora esta matriz, resulta más fácil ver si el algoritmo está fallando en una frontera específica de uso clínico o si el problema es global. Sin esta organización el servicio puede tener muchas mediciones y poca claridad.
El papel de los fantasmas heterogéneos
La heterogeneidad no puede dejarse únicamente al caso clínico real. Cuando un servicio pretende utilizar algoritmos más sofisticados precisamente por cuestiones de pulmón, hueso, caries o implantes, necesita probar el conjunto de geometrías que obligan al motor a afrontar estos fenómenos.
Los materiales locales utilizados aquí refuerzan esta necesidad:
- Eclipse explica las limitaciones pulmonares;
- RayStation describe validaciones en geometrías homogéneas y heterogéneas, incluso con IAEA conjunto de pruebas, AAPM TG105 y comparación con EGSnrc;
- el manual muestra puntos de referencia donde la diferencia entre AAA y Acuros XB aparece claramente en heterogeneidades de baja densidad.
Esto sugiere una regla simple: si el servicio quiere confiar en las ganancias de rendimiento derivadas de la heterogeneidad, necesita validar la heterogeneidad con intención, no por inferencia.
Gamma no resuelve todo
Gamma sigue siendo útil, pero a menudo se usa como un atajo mental. Un motor puede pasar gamma global y aún ocultar diferencias clínicamente relevantes en regiones pequeñas, interfaces o materiales específicos.
RayStation utiliza criterios como 95% de puntos con gamma 3%, 3 mm < 1, y esto tiene sentido como parte del proceso de validación. Pero la lectura madura no termina ahí. Un conjunto de pruebas necesita combinar:
- gamma;
- diferencias de puntos;
- perfiles de lectura;
- atención a las regiones de gradiente;
- análisis de heterogeneidad;
- interpretación clínica de la localización de la discrepancia.
Si gamma pasa, pero la diferencia relevante es exactamente en el pulmón distal, en el hueso o al lado de un implante, el problema no desaparece.
El QA por paciente no reemplaza el QA del algoritmo
Otro error común es utilizar QA por paciente como si pudiera compensar cualquier laguna en la comprensión del motor de dosis. No puede.
QA por paciente generalmente responde a una pregunta más concreta: si el plan calculado y entregado mantiene coherencia dentro de una disposición específica de criterios de medición y comparación.
No reemplaza:
- validación del algoritmo en heterogeneidad;
- comprender la convención de dosis;
- análisis de beam model;
- alcance formal de puesta en marcha de la técnica.
Cuando el servicio utiliza QA por paciente como muleta para una duda algorítmica estructural, corre el riesgo de validar repetidamente la misma hipótesis débil.
Cuando comparar algoritmos es realmente útil
Comparar motores tiene sentido cuando la institución quiere responder preguntas concretas, por ejemplo: ¿
- AAA y Acuros XB cambia la cobertura en pequeños pulmones de alta energía?
- CC y MC por RayStation divergen en un sitio con hueso o alto Z?
- ¿el cambio de motor cambia la interpretación de la dosis de fondo o la reirradiación?
- ¿la diferencia observada pertenece al transporte o a la convención de dosis?
Esa es la buena comparación: basada en hipótesis.
La mala comparación es aquella que busca demostrar, de forma genérica, que “el algoritmo A es mejor que el algoritmo B” sin declarar escenario, técnica, material y beam model.
Una hoja de ruta mínima para comparar rigurosamente algoritmos
Si la institución quiere hacer esto bien, una hoja de ruta mínima incluye:
- hacer coincidir o justificar la cuadrícula y la imagen;
- comprobar si los beam models son maduros;
- declara la convención de dosis para cada motor;
- separa las pruebas homogéneas de las pruebas heterogéneas;
- incluir al menos un escenario clínicamente crítico para el servicio;
- evaluar perfiles, profundidad, dosis local y no solo DVH;
- registra en qué situaciones la diferencia cambia la decisión y en cuáles no.
Este script ya filtra gran parte del ruido metodológico que tiende a aparecer en las discusiones informales sobre TPS.
Lo que la literatura y los manuales enseñan juntos
Al leer uno al lado del otro los documentos locales utilizados en este grupo, aparece un mensaje convergente.
Eclipse muestra que diferentes algoritmos tienen diferentes fundamentos y limitaciones conocidas. RayStation muestra que coexisten diferentes motores con alcances de validación específicos y convenciones de dosis potencialmente diferentes. El manual muestra que el rendimiento relativo entre familias algorítmicas cambia según la heterogeneidad y la física dominante del caso.
En conjunto, estos materiales dejan una conclusión incómoda pero importante: si la comparación entre algoritmos se realizó sin indicar el resto de la cadena de modelado, la conclusión probablemente se sobreinterprete.
El verdadero beneficio de una comparación bien hecha
Cuando la comparación está bien hecha, deja de producir eslóganes y empieza a producir límites de confianza. En otras palabras:
- en qué escenarios es suficiente el algoritmo A;
- en qué escenarios vale la pena recalcular con B;
- en qué escenarios la diferencia observada es realmente física;
- en qué escenarios es simplemente metodológico.
Este tipo de respuesta vale más para la clínica que cualquier clasificación genérica entre TPS. Al final, esto es lo que una puesta en marcha decente debería ofrecer: no un “algoritmo ganador”, sino un mapa honesto de dónde cada combinación de motor + beam model + todavía responde bien y dónde ya necesita validación adicional, recálculo o cambio de estrategia.