There is a very efficient way to produce confusion in clinical physics: recalculate the same case on two engines, open DVHs side by side, and treat any difference as evidence. In almost every service, this is how phrases like “algorithm X calculates more dose” or “algorithm Y is more conservative” are born. The comparison is almost never clean enough to support this.
The reason is simple. When two results differ, what is being compared is not just the name of the engine. They usually include beam model, grid resolution, material mapping, dose convention, MLC parameters and even the validation scope of that technique on the real machine.
This is why this part of the cluster is so routine. Understand AAA, Acuros XB, collapsed cone and Monte Carlo is important. Knowing how to compare these engines without making mistakes with the methodology itself is what really changes the practice.
In this Article
- 1. The first mistake: thinking that algorithm is equal to result
- 2. Beam model: the invisible part of the comparison
- 3. The second error: comparing different grids as if they were the same thing
- 4. The third mistake: ignoring the dose convention
- 5. The fourth error: treating the technique as if it were automatically validated
- 6. What commissioning should really answer
- 7. A matrix of tests is better than a pile of disconnected measurements
- 8. The role of heterogeneous phantoms
- 9. Gamma doesn’t solve everything
- 10. QA per patient does not replace QA from the algorithm
- 11. When comparing algorithms is really useful
- 12. A minimum roadmap to rigorously compare algorithms
- 13. What literature and manuals teach together
- 14. The real gain of a well-made comparison
The first mistake: thinking that algorithm is equal to result
The algorithm matters a lot, but it never works alone. In any serious commercial TPS, the result that appears on the screen depends on at least five layers:
- beam model (beam model);
- commissioning and measurement data;
- resolution and discretization;
- representation of the patient and materials;
- dose reporting convention.
When someone says that “algorithm X gave a higher dose than algorithm Y”, the sentence is incomplete. What gave the greatest dose was a whole set of choices: engine, model, grid, material mapping, technique, machine and, sometimes, different dose magnitude.
Beam model: the invisible part of the comparison
beam model is one of the most underestimated factors in TPS comparisons. It defines how the system describes:
- the primary source;
- extra-focal photons;
- electronic contamination;
- collimators;
- MLC;
- wedges;
- output factors;
- geometric and dosimetric parameters of the beam.
Eclipse makes this clear by showing that AAA and Acuros XB share the same photon beam source model. RayStation insists, in its IFU, that certain scenarios, especially small field rotational plans, are highly sensitive to MLC parameters of beam model.
This observation is decisive. Sometimes the physicist believes he is seeing a difference in algorithmic family, when in fact he is seeing:
- difference in MLC modeling;
- commissioning difference;
- source parameterization difference.
Without isolating these layers, the comparison becomes a mixture of causes.
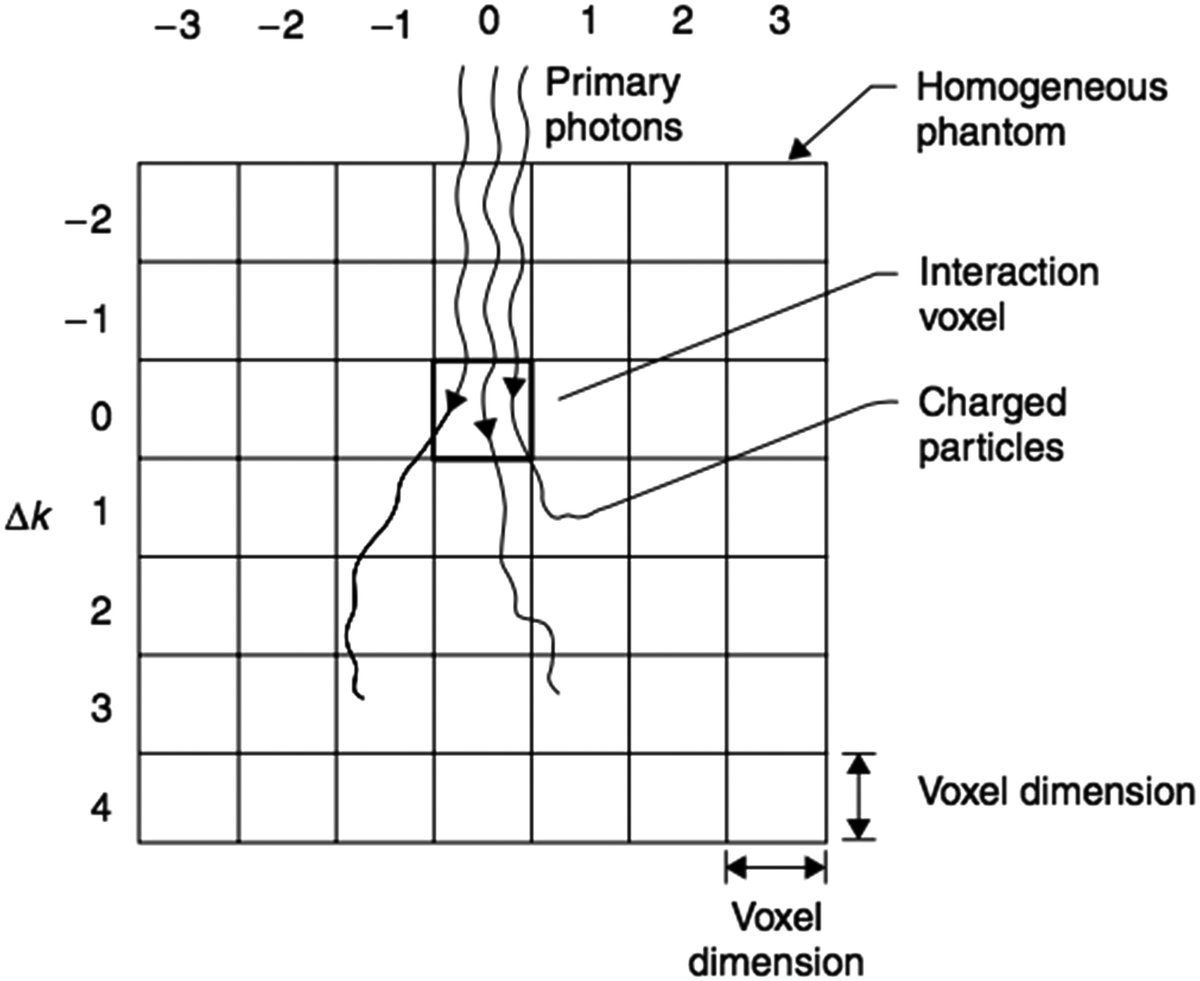
The second error: comparing different grids as if they were the same thing
Dose resolution is not a cosmetic detail. It changes:
- gradient sampling;
- definition of penumbra;
- dose in small volumes;
- behavior in interfaces;
- appearance of agreement between algorithms.
AAA uses divergent grid internally and depends on the chosen resolution ratio, pixel spacing and separation between cuts. Acuros XB uses variable spatial discretization with adaptive refinement. Monte Carlo, in turn, also brings the additional component of statistical noise per voxel.
This means that comparing two algorithms without equalizing the output mesh, or without at least understanding how each one discretizes the problem internally, is methodologically fragile.
A useful rule of thumb is this: before discussing physics, align discretization.
The third mistake: ignoring the dose convention
This point becomes increasingly important as services start to use material-explicit algorithms.
Acuros XB allows dose to medium and dose to water. THE RayStation, in the local material, warns that the photon collapsed cone computes dose for water, while the photon Monte Carlo reports dose for medium. The same document explicitly warns about the risk of combining or comparing different engine distributions when the case is sensitive to high Zmaterials.
If the service ignores this, what looks like algorithmic divergence may be, in part, reported physical quantity divergence.
In practical terms, before comparing any dose between engines, the physicist needs to answer:
- are the two engines reporting the same convention?
- Is the expected difference between conventions small in this material?
- Is there bone, implant or other material that amplifies this discrepancy?
Without these questions, even a pretty DVH could be misinterpreted.
The fourth error: treating the technique as if it were automatically validated
IFU from RayStation is very useful because it speaks the language that every service should adopt. The document reminds us that certain techniques, such as VMAT sequencing, must be treated as practically a new technique, requiring:
- validation of beam model;
- machine behavior validation;
- QA per patient.
This observation should be universalized. The fact that an algorithm works very well on 3D-CRT does not automatically guarantee the same behavior on:
- IMRT fixed;
- VMAT;
- wave arcs;
- fields too small;
- platform specific techniques.
Whenever the technique changes, the validity of the set algorithm + beam model + delivery needs to be re-evaluated.
What commissioning should really answer
Instead of treating commissioning as a generic checklist, it’s worth asking the right questions.
A serious commissioning needs to show:
- whether the engine reproduces dose depth, profiles and machine output factors;
- whether the behavior is maintained in small fields;
- whether the algorithm responds correctly in heterogeneous media relevant to the local clinic;
- if the modeling of MLC is adequate;
- if the grid and image choices do not introduce relevant artifacts;
- if the dose convention adopted is known and consistent.
In other words, commissioning is not “making the algorithm pass”. It’s finding out in which territory that set can be used with confidence.
A matrix of tests is better than a pile of disconnected measurements
Instead of thinking of commissioning as a collection of data, it’s worth thinking of it as a matrix of questions. A useful minimum matrix usually crosses:
- open field and small field;
- homogeneous and heterogeneous;
- center axis and off axis;
- simple technique and modulated technique;
- water-equivalent material and clinically challenging material.
When the team puts together this matrix, it becomes easier to see if the algorithm is failing at a specific frontier of clinical use or if the problem is global. Without this organization, the service may have many measurements and little clarity.
The role of heterogeneous phantoms
Heterogeneity cannot be left only to the real clinical case. When a service intends to use more sophisticated algorithms precisely because of lung, bone, cavities or implants, it needs to test the set in geometries that force the engine to deal with these phenomena.
The local materials used here reinforce this need:
- Eclipse explains lung limitations;
- RayStation describes validations in homogeneous and heterogeneous geometries, including with IAEA test suite, AAPM TG105 and comparison with EGSnrc;
- the handbook shows benchmarks where the difference between AAA and Acuros XB appears clearly in low density heterogeneities.
This suggests a simple rule: if the service wants to rely on performance gains from heterogeneity, it needs to validate heterogeneity with intent, not by inference.
Gamma doesn’t solve everything
Gamma remains useful, but is often used as a mental shortcut. A motor can pass global gamma and still hide clinically relevant differences in small regions, interfaces, or specific materials.
RayStation uses criteria like 95% of points with gamma 3%, 3 mm < 1, and this makes sense as part of the validation process. But mature reading doesn’t stop there. A test suite needs to combine:
- gamma;
- point differences;
- reading profiles;
- attention to gradient regions;
- heterogeneity analysis;
- clinical interpretation of the location of the discrepancy.
If gamma passes, but the relevant difference is exactly in the distal lung, in the bone or next to an implant, the problem does not disappear.
QA per patient does not replace QA from the algorithm
Another common mistake is to use QA per patient as if it could compensate for any gaps in understanding the dose engine. It cannot.
QA per patient generally answers a narrower question: whether the calculated and delivered plan maintains coherence within a specific arrangement of measurement and comparison criteria.
It does not replace:
- validation of the algorithm in heterogeneity;
- understanding the dose convention;
- analysis of beam model;
- formal scope of commissioning of the technique.
When the service uses QA per patient as a crutch for a structural algorithmic doubt, it runs the risk of repeatedly validating the same weak hypothesis.
When comparing algorithms is really useful
Comparing engines makes sense when the institution wants to answer concrete questions, for example: do
- AAA and Acuros XB change coverage in small high-energy lungs?
- CC and MC from RayStation diverge at a site with bone or high Z?
- does the change of engine change the interpretation of background dose or re-irradiation?
- does the observed difference belong to transport or dose convention?
That’s the good comparison: hypothesis-driven.
The bad comparison is the one that seeks to prove, in a generic way, that “algorithm A is better than algorithm B” without declaring scenario, technique, material and beam model.
A minimum roadmap to rigorously compare algorithms
If the institution wants to do this right, a minimum roadmap includes:
- matching or justifying grid and image;
- check if beam models are mature;
- declare the dose convention for each engine;
- separate homogeneous tests from heterogeneous tests;
- include at least one clinically critical scenario for the service;
- evaluate profiles, depth, local dose and not only DVH;
- record in which situations the difference changes the decision and in which it does not.
This script already filters out much of the methodological noise that tends to appear in informal discussions about TPS.
What literature and manuals teach together
Reading the local documents used in this cluster side by side, a convergent message appears.
Eclipse shows that different algorithms have different fundamentals and known limitations. RayStation shows that different engines coexist with specific validation scopes and potentially different dose conventions. The handbook shows that the relative performance between algorithmic families changes according to the heterogeneity and dominant physics of the case.
Together, these materials leave an uncomfortable but important conclusion: if the comparison between algorithms was made without stating the rest of the modeling chain, the conclusion is probably overinterpreted.
The real gain of a well-made comparison
When the comparison is well-made, it stops producing slogans and starts producing trust boundaries. In other words:
- in which scenarios is algorithm A sufficient;
- in which scenarios is it worth recalculating with B;
- in which scenarios the observed difference is actually physical;
- in which scenarios it is just methodological.
This type of answer is worth more to the clinic than any generic ranking among TPS. In the end, this is what a decent commissioning should deliver: not a “winning algorithm”, but an honest map of where each engine + beam model + technique combination still responds well and where it already needs extra validation, recalculation or change of strategy.