

Neste Guia
- 1. Requisitos do Cálculo de Dose Moderno
- 2. Geometria do Paciente e Scaling de Densidade
- 3. Calibração e Dose na Água vs. Dose no Tecido
- 4. Classificação dos Algoritmos
- 5. Métodos Empíricos Broad-Beam
- 6. Separação Primário-Espalhamento e Clarkson
- 7. Convolução de Kernels e TERMA
- 8. Collapsed Cone Convolution
- 9. Pencil Beam e AAA
- 10. Monte Carlo e Acuros
- 11. Comparação na Prática Clínica
Qual algoritmo de cálculo de dose seu TPS está realmente usando — e quais são as consequências disso para o paciente? Essa pergunta deveria manter todo físico médico atento. Os algoritmos de cálculo de dose por fótons evoluíram dramaticamente nas últimas décadas, partindo de correções empíricas tabulares até simulações de transporte de partículas que modelam cada interação individualmente. Neste guia, percorremos toda essa jornada: dos métodos broad-beam e collapsed cone convolution até os cálculos de dose com Monte Carlo e Acuros, mostrando onde cada abordagem brilha e onde falha.
Entender essas diferenças não é exercício acadêmico. Na era do IMRT e VMAT, o algoritmo de cálculo determina diretamente se a otimização inversa converge para uma solução clinicamente aceitável. Um pencil beam pode superestimar a cobertura de PTV em pulmão por até 10% comparado a um Monte Carlo — e essa discrepância pode mudar a decisão clínica. Os sistemas de planejamento modernos oferecem múltiplos algoritmos, e o físico médico precisa saber escolher o mais adequado para cada cenário.
Requisitos do Cálculo de Dose na Radioterapia Moderna
O cálculo de dose no paciente precisa ser preciso, rápido e abrangente. Parece simples, mas esses três requisitos competem entre si constantemente. Desde os primeiros capítulos do Handbook of Radiotherapy Physics, Rosenwald enfatiza que o objetivo final dos algoritmos é predizer acuradamente a dose entregue dentro das estruturas anatômicas do paciente — dose alta o suficiente no tumor para destruir células malignas, mas abaixo do limiar aceitável para tecidos normais.
Quanto de precisão é necessário? Ahnesjö e Aspradakis (1999) analisaram essa questão de forma elegante em um artigo que permanece referência até hoje. O cálculo de dose é apenas um elo numa cadeia de incertezas que vai da calibração do feixe até o posicionamento do paciente. A incerteza combinada ($k=1$) dessa cadeia, excluindo o cálculo de dose, fica em torno de 4,1% com a técnica atual. Adicionando uma incerteza de cálculo de 2% a 3%, a incerteza global sobe marginalmente — de 4,1% para 4,6% ou 5,1%. Já uma incerteza de cálculo de 5% eleva o total para 6,5%, o que se torna clinicamente relevante e inaceitável.
Tabela de Incertezas no Cálculo de Dose
| Fonte de incerteza | Técnica atual (% ΔD/D) | Futuro (% ΔD/D) |
|---|---|---|
| Dose absorvida no ponto de calibração | 2,0 | 1,0 |
| Incerteza adicional para outros pontos | 1,1 | 0,5 |
| Estabilidade do monitor | 1,0 | 0,5 |
| Planicidade do feixe | 1,5 | 0,8 |
| Incertezas dos dados do paciente | 1,5 | 1,0 |
| Setup feixe e paciente | 2,5 | 1,6 |
| Global excluindo cálculo de dose | 4,1 | 2,4 |
| Cálculo de dose (alvo razoável) | 2,0–3,0 | 1,0 |
| Incerteza global resultante | 4,6–5,1 | 2,6 |
Fonte: Adaptado de Ahnesjö & Aspradakis, Phys. Med. Biol., 44, R99–R155, 1999. Incertezas expressas como k=1.
Esse valor de ~2% é considerado razoável para a técnica atual. Quase 20 anos após essa publicação, a precisão dosimétrica em cada etapa anterior ao cálculo não melhorou dramaticamente — portanto, conforme Van Dyk e Battista (2014), a coluna “técnica presente” continua representativa da realidade clínica.
A velocidade é o outro lado da moeda. Com a distribuição 3D completa sendo exigida para todos os feixes simultaneamente, o poder computacional nunca parece suficiente. Para o planejamento interativo forward, o tempo de resposta deve ficar entre 10 e 20 segundos para que o planner consiga avaliar visualmente as mudanças de dose ao modificar parâmetros do feixe. Com o IMRT, a demanda é ainda mais extrema: o cálculo precisa ser repetido para dezenas de feixes, centenas de iterações, em milhares de pontos.
Acelerar o cálculo quase sempre significa sacrificar precisão — para um dado hardware. A escolha do algoritmo em cada situação clínica é, portanto, um compromisso consciente. Uma solução prática adotada em muitos serviços: usar um algoritmo rápido durante a otimização inversa e depois confirmar a distribuição de dose final com um algoritmo mais preciso (por exemplo, otimizar com pencil beam e verificar com Monte Carlo). Porém, se o algoritmo rápido tiver limitações significativas, a otimização pode convergir para uma solução que o algoritmo preciso rejeita — gerando retrabalho.
Geometria do Paciente e Scaling de Densidade
O cálculo de dose em qualquer ponto do paciente começa pela geometria. A representação mais eficaz da anatomia é uma matriz 3D de voxels derivada de uma tomografia computadorizada (CT) na posição de tratamento. Idealmente, a densidade e composição exata de cada voxel deveriam ser consideradas, mas simplificações são inevitáveis.
Como primeira aproximação, basta calcular a espessura de tecido ao longo da linha que liga a fonte ao ponto de cálculo — isso dá conta do componente primário. O conceito de caminho equivalente (equivalent path length) é intuitivo: o produto $t_m \times \rho_m$ de uma espessura $t_m$ de material $m$ pela sua densidade $\rho_m$ produz aproximadamente a mesma atenuação para fótons que o produto $t_w \times \rho_w$ em água ($\rho_w = 1$):
$$t_w = t_m \times \rho_m$$
Essa equivalência é rigorosa para o componente primário de um feixe polienergético, desde que a densidade seja expressa como densidade eletrônica relativa à água e apenas interações Compton sejam consideradas. Para tecidos como osso ou pulmão (que contém ar), o conteúdo de hidrogênio difere da água; nesses casos, é preferível usar o scaling por densidade eletrônica (Seco e Evans 2006).
Para precisão maior, precisamos considerar também os fótons espalhados e os elétrons secundários. O teorema de O’Connor (1957) estende o método de caminho equivalente para as dimensões laterais: quando dois meios de densidades diferentes mas mesma composição atômica são expostos ao mesmo feixe, a dose em pontos correspondentes nos dois meios será a mesma desde que todas as distâncias geométricas — incluindo tamanhos de campo — sejam escaladas inversamente com a densidade. Esse resultado é importante conceitualmente, mas de aplicação prática limitada em pacientes reais, onde a composição atômica varia.
Para elétrons secundários e feixes de partículas carregadas, considerações similares de scaling baseadas em razões de stopping power podem ser úteis (teorema de Fano). A transformação do sistema de coordenadas do paciente ($X_p, Y_p, Z_p$) para o sistema do feixe segue o padrão IEC 61217:2011 — uma estrutura hierárquica de sistemas cartesianos para paciente, gantry, colimador e mesa. A escolha do tamanho do grid de cálculo é um compromisso entre velocidade e precisão (Niemierko e Goitein 1989).
Com scanners CT disponíveis, a geometria baseada em voxels (bitmap) substituiu a representação vetorial que usava contornos mecânicos. Cada voxel carrega sua densidade; o caminho equivalente é calculado pela soma dos produtos $t_i \times \rho_i$ ao longo da linha fonte-ponto, onde $t_i$ é a distância geométrica e $\rho_i$ a densidade de cada voxel atravessado.
Calibração e o Debate Dose na Água vs. Dose no Tecido
Todo algoritmo de cálculo de dose deve ser capaz de fornecer a dose absoluta (em Gy) para um dado número de unidades monitoras (UM). Na prática, os algoritmos calculam distribuições relativas, normalizadas a um ponto de referência — o isocentro, o ponto ICRU ou a profundidade de máximo ($d_{max}$). A ligação entre dose relativa e absoluta é feita por um processo de calibração interna.
O TPS simula as condições de calibração do feixe (incidência normal em fantoma de água, distância e campo de referência) e calcula a dose relativa $D_{ref,calc}^{rel}$ (em unidades arbitrárias). A dose medida $D_{ref,meas}$ (em Gy/UM) é fornecida durante o commissioning. O coeficiente de calibração interna fica:
$$k_c = \frac{D_{ref,meas}}{D_{ref,calc}^{rel}} \quad (\text{Gy} \cdot \text{UM}^{-1} \cdot \text{u.a.}^{-1})$$
A dose absoluta em qualquer ponto $(x,y,z)$ para qualquer situação é então $D(x,y,z) = k_c \cdot D^{rel}(x,y,z)$ em Gy/UM. Uma verificação fundamental e simples: calcular a dose nas condições de referência para um dado número de UMs e confirmar que coincide com a dose medida (tipicamente dentro de 0,1%).
O debate sobre reportar dose na água ($D_w$) ou dose no tecido ($D_t$) tem dimensões clínicas e históricas importantes. A favor de $D_w$: a maior parte da experiência clínica e dos ensaios clínicos se baseia nessa quantidade. A favor de $D_t$: é a dose “real” e, portanto, mais relevante para avaliação clínica. A diferença prática para tecidos moles é de ~1% (o fator 0,99), mas para osso compacto pode chegar a 6–11% dependendo do método de conversão utilizado.
Andreo (2015) conduziu uma investigação rigorosa sobre os métodos de conversão e concluiu que é importante considerar as modificações da fluência eletrônica entre tecido real e tecido “water-like”. Como a modificação da fluência é oposta à modificação da razão de stopping power, o coeficiente de conversão é geralmente superestimado quando a correção de fluência é ignorada. Considerando que: (i) a composição atômica real do tecido não é conhecida com precisão, (ii) a diferença prática para casos clínicos entre $D_w$ e $D_t$ é pequena, e (iii) os métodos de conversão implementados na maioria dos TPS são aproximações grosseiras — Andreo e outros (incluindo Ma e Li 2011) recomendam simplesmente reportar $D_t$ para cálculos Monte Carlo.
O relatório TG-329 da AAPM (2020) tenta fechar essa questão: recomenda que todas as máquinas sejam calibradas em dose na água, mas que futuros TPS especifiquem dose no tecido, aplicando a correção de 0,99 para tecido mole tanto para fótons quanto para elétrons, se o sistema não a aplicar automaticamente. Cada serviço deve verificar como seu TPS se comporta e tomar uma decisão consciente.
Classificação dos Algoritmos de Cálculo de Dose por Fótons
Não existe consenso absoluto sobre como classificar os algoritmos de cálculo de dose. Vários autores propuseram esquemas diferentes, e a realidade é que muitos algoritmos comerciais combinam elementos de diferentes categorias.
A classificação do ICRU (1987) distinguia entre formatos tabulares (ou de matriz), funções geradoras de feixe, separação de radiação primária e espalhada, e representações usando princípios básicos. Mackie et al. (1995) simplificaram para duas categorias: métodos baseados em correção (correction-based) — que partem de uma distribuição de dose em feixe aberto em água e aplicam fatores de correção para modificadores de feixe e características do paciente — e métodos baseados em modelo (model-based) — que computam diretamente a interação no paciente. Lu (2013) adicionou uma terceira categoria: métodos baseados em princípios, referindo-se especificamente à simulação computacional do transporte de partículas (Monte Carlo e métodos determinísticos). O relatório ICRU 91 (2017) sugeriu que a categoria correction-based fosse renomeada para “factor-based”.
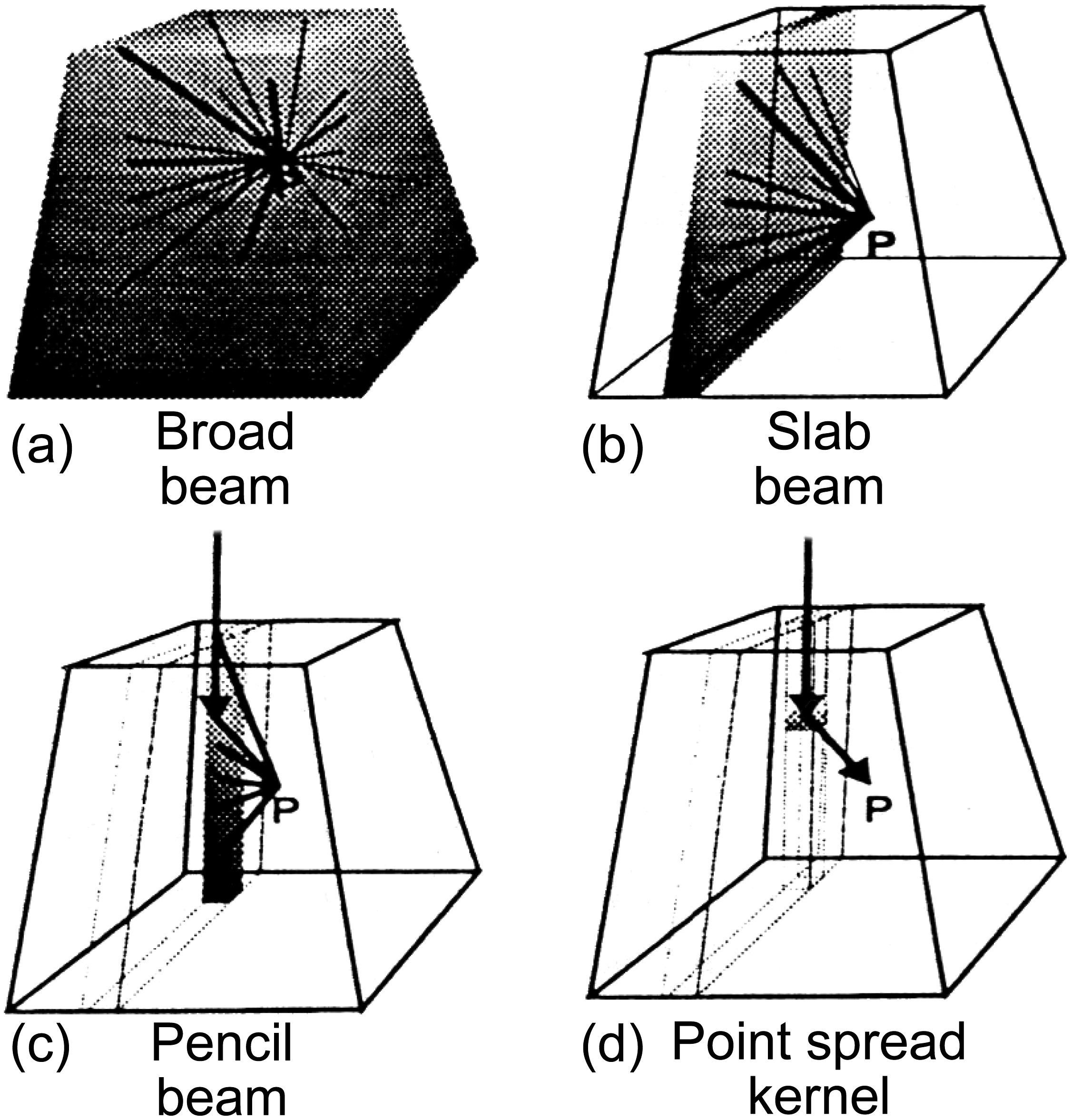
Battista et al. (1997) propuseram uma classificação segundo a dimensionalidade da integração dos kernels. Sem integração (broad beam — feixe tratado como um todo), 1D (slab beam), 2D (pencil beam) e 3D (point spread kernel). Essa classificação é particularmente útil para entender a progressão dos algoritmos e tem a vantagem de ser concreta.
Talvez a distinção mais útil clinicamente foi proposta por Knöös et al. (2006), que separaram algoritmos tipo “a” — que assumem deposição local de energia, ignorando o transporte de elétrons secundários a distância do ponto de interação — dos tipo “b” — que tratam esse transporte explicitamente. Algoritmos tipo “a” incluem broad-beam, Clarkson e algumas implementações de pencil beam. Algoritmos tipo “b” incluem CCC, AAA, Monte Carlo e Acuros. Essa diferença se torna clinicamente relevante em interfaces tecido-pulmão, campos pequenos de alta energia e qualquer situação com falta de equilíbrio eletrônico.
Métodos Empíricos Broad-Beam: Onde Tudo Começou
Os métodos broad-beam foram a primeira geração de algoritmos de cálculo de dose para planejamento clínico computadorizado. A ideia é direta: o feixe é tratado como um todo, sem ser decomposto em componentes menores. Dados experimentais — representações tabulares como PDD, TAR, TMR, TPR — e representações analíticas parametrizadas formam a base do cálculo.
Para feixes simples em água, os dados tabulados fornecem a dose para qualquer combinação de profundidade, tamanho de campo e distância. Para o paciente real, correções são aplicadas progressivamente. A correção para forma do paciente lida com o fato de que a superfície do paciente não é plana nem perpendicular ao feixe. O método da SSD efetiva usa a profundidade corrigida pela superfície para consultar tabelas de PDD. O método baseado em TPR é mais preciso para técnicas isocêntricas e menos sensível à forma da superfície, pois usa a razão de dose em profundidade em relação a um ponto de referência.
Para heterogeneidades, os métodos empíricos oferecem várias opções com graus crescentes de sofisticação. A correção por TAR de profundidade efetiva simplesmente calcula o caminho equivalente em água e consulta a TAR com essa profundidade. A correção power-law de Batho vai além, usando razões de TARs elevadas a potências que dependem da densidade relativa do tecido. O método é razoavelmente preciso para pontos distantes de interfaces, mas falha próximo a bordas entre tecidos de densidades diferentes. O ETAR (Equivalent Tissue-Air Ratio) tenta fazer um scaling de campo efetivo para corrigir também o espalhamento lateral, e o beam subtraction method calcula a diferença entre o espalhamento com e sem a heterogeneidade.
A limitação fundamental de todos os métodos broad-beam é que eles assumem deposição local de energia — ignoram completamente o transporte lateral de elétrons secundários. Funcionam razoavelmente em tecido homogêneo e para campos de dimensões normais, mas falham sistematicamente nas situações onde mais precisamos de precisão: interfaces tecido-pulmão com campos pequenos de alta energia e regiões com falta de equilíbrio eletrônico lateral. Para um mergulho técnico nas equações, derivações e limitações dos métodos empíricos, confira nosso artigo dedicado sobre métodos broad-beam no cálculo de dose.
Separação Primário-Espalhamento e o Método de Clarkson
A separação primário-espalhamento representa o primeiro passo conceitual em direção a métodos mais sofisticados. A ideia é decompor a dose total em dois componentes: dose primária (fótons que chegam ao ponto de cálculo sem ter interagido — tipicamente mais de 70% da dose total) e dose espalhada (fótons que sofreram uma ou mais interações no meio — até 30% da dose). A esses dois componentes somam-se a contribuição do head scatter (5–10%) e dos elétrons contaminantes (relevante apenas na região de build-up).
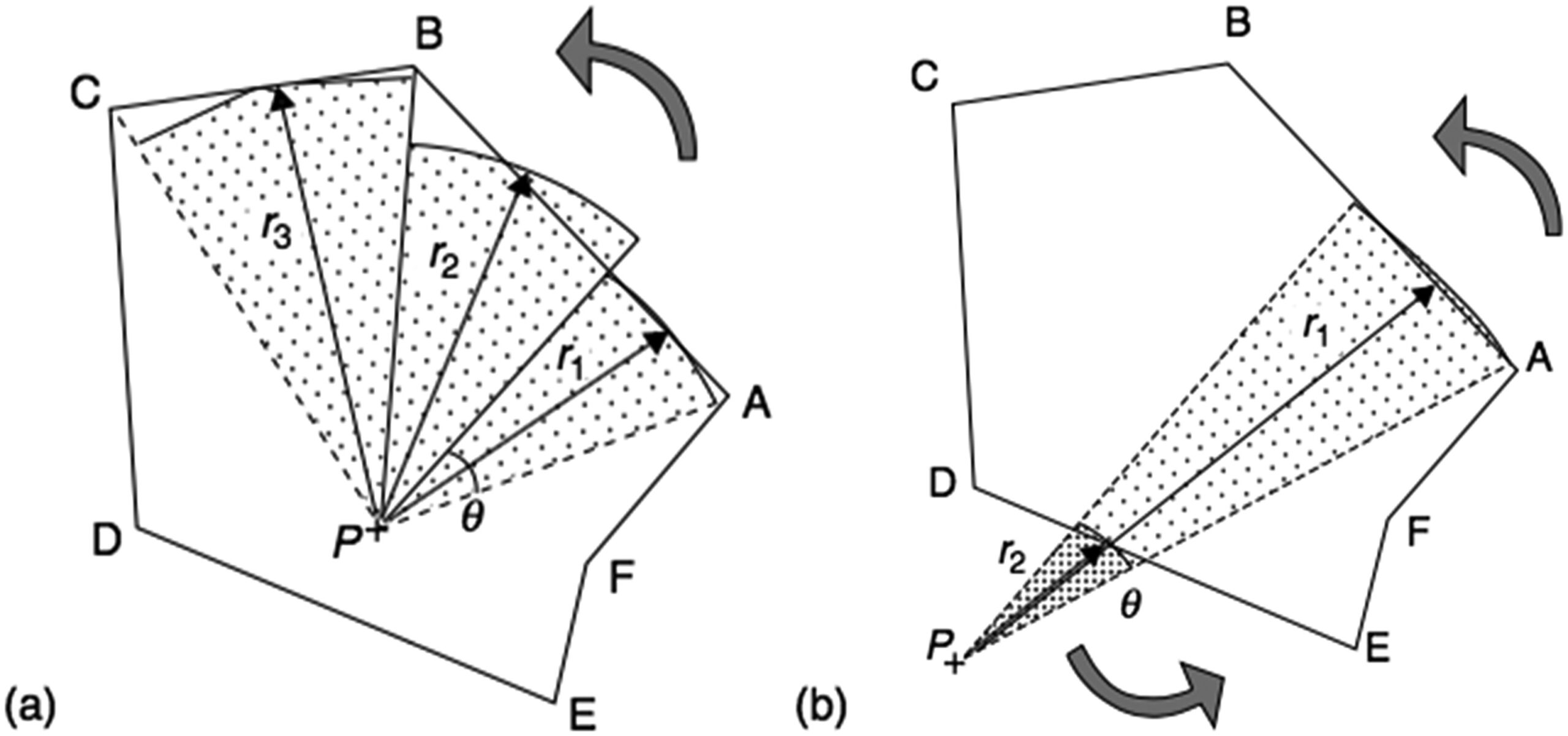
O método de Clarkson calcula o espalhamento por integração setorial. O campo é dividido em $n$ setores angulares centrados no ponto de cálculo. Para cada setor $i$ com largura angular $\Delta\theta_i$ e raio $r_i$ até a borda do campo, o SAR (scatter-air ratio) é interpolado de tabelas para campos circulares e ponderado pela fração angular:
$$D_S(x,y,z) = D_A(z) \sum_i S(z,r_i) \frac{\Delta\theta_i}{2\pi}$$
onde $D_A(z)$ é a dose “no ar” na posição $(0,0,z)$ e $S(z,r_i)$ é o scatter-air ratio para profundidade $z$ e raio $r_i$. A dose primária usa o TAR de campo zero ($TAR_0$), uma abstração matemática obtida por extrapolação de TARs para campos progressivamente menores até zero.
Quando o ponto de cálculo está fora do campo, o procedimento é análogo, mas as contribuições são somadas com sinais conforme a orientação dos setores — setores varridos da direita para a esquerda (contribuição positiva dentro do campo) e da esquerda para a direita (subtração fora do campo), mantendo apenas a contribuição da área irradiada.
Uma extensão importante: quando a superfície é oblíqua ou o feixe é não-uniforme (modulado por filtro de cunha ou compensador), a integração 1D angular de Clarkson pode ser substituída por uma integração 2D de elementos pencil-like de espalhamento. Cada elemento de espalhamento $\Delta S_{ij}$ é referenciado a um sistema polar centrado no ponto de cálculo e ponderado pela fluência primária local. Esse refinamento funciona satisfatoriamente para IMRT com colimadores multi-leaf (Papatheodorou et al. 2000).
Os métodos de separação primário-espalhamento oferecem resultados precisos em meios homogêneos para campos de dimensões maiores que o tamanho mínimo equivalente ($ESQ_{min}$). Porém, assim como os broad-beam, eles assumem caminho de elétrons secundários desprezível e falham em interfaces de heterogeneidades quando o transporte eletrônico é significativo — especialmente fótons de alta energia em pulmão (Mohan e Chui 1985; AAPM 2004). Para um aprofundamento no princípio da superposição, Clarkson e o conceito de TERMA, leia nosso artigo sobre superposição e TERMA no cálculo de dose.
Convolução de Kernels e o Conceito de TERMA

A convolução/superposição de kernels marcou uma mudança de paradigma no cálculo de dose para planejamento de tratamento. A ideia foi proposta independentemente por vários grupos em 1984 — Ahnesjö, Boyer & Mok, Chui & Mohan, e Mackie & Scrimger — e unifica a descrição da deposição de dose em torno de dois conceitos fundamentais: o TERMA e os kernels de deposição de energia.
Para um meio homogêneo, a dose em um ponto $\mathbf{r}=[x,y,z]$ é expressa pela equação de convolução:
$$D(\mathbf{r}) = \iiint \Psi(\mathbf{r’}) \frac{\mu}{\rho}(\mathbf{r’}) \, K(\mathbf{r} – \mathbf{r’}) \, dV’$$
O termo $\Psi(\mathbf{r’}) \cdot \mu/\rho(\mathbf{r’})$ é o TERMA — Total Energy Released per unit MAss — no ponto $\mathbf{r’}$. Expresso em J/kg (ou Gy), representa toda a energia (elétrons secundários e fótons espalhados) liberada por unidade de massa naquele ponto. É o análogo volumétrico do kerma, mas aplicado à condição real do feixe dentro do paciente.
O kernel $K(\mathbf{r} – \mathbf{r’})$ descreve a fração de energia liberada em $\mathbf{r’}$ que se deposita no ponto $\mathbf{r}$. Esse kernel — também chamado de dose-spread array ou point-spread function — incorpora o transporte dos elétrons secundários e fótons espalhados. A integração é feita em 3D sobre todo o volume do paciente.
A fluência energética $\Psi$ que entra no paciente depende de várias fontes no cabeçote do acelerador. Para um LINAC típico, os fótons primários de bremsstrahlung emitidos do alvo constituem a fonte principal. A esses se somam a radiação extrafocal (fótons espalhados pelo filtro aplainador e pelo colimador) e os elétrons contaminantes das interações no cabeçote e no ar. Um modelo de três fontes — alvo puntiforme, filtro como fonte extrafocal gaussiana e superfície do paciente como fonte de contaminação eletrônica — cobre a maioria dos cenários clínicos.
Para feixes polienergéticos reais, a integração deve ser realizada sobre os bins de energia do espectro local do feixe, já que tanto $\mu/\rho$ quanto os kernels dependem da energia. Simplificar para uma energia média equivalente não é suficientemente preciso, mas um número limitado de bins (4–6) funciona bem na prática (Boyer et al. 1989; Zhu e Van Dyk 1995).
A convolução direta 3D é computacionalmente proibitiva — o número de operações escala como $N^6$ para $N^3$ voxels. Quando o kernel é invariante no espaço (meio homogêneo), a transformada rápida de Fourier (FFT) reduz o custo para $N^3 \log N$. Em meios heterogêneos, porém, o kernel muda ponto a ponto. A solução? Métodos que aproximam a variação do kernel sem perder o essencial — e o mais bem-sucedido deles é o Collapsed Cone Convolution.
Collapsed Cone Convolution: Eficiência com Precisão
O algoritmo Collapsed Cone Convolution (CCC), proposto por Ahnesjö em 1989, é uma das soluções mais elegantes para o problema da superposição de kernels em meios heterogêneos. A ideia central: em vez de avaliar o kernel completo em todas as direções para cada ponto, o espaço é dividido em um número finito de cones sólidos e toda a energia transportada dentro de cada cone é “colapsada” sobre o eixo do cone.
Os kernels de deposição de energia foram originalmente gerados por simulação Monte Carlo por Mackie et al. (1988), num trabalho seminal que calculou a deposição de energia ponto a ponto ao redor de um sítio de primeira interação forçada em água. Esses kernels têm uma estrutura característica: um pico central intenso (deposição local pelos elétrons secundários, que domina a dose próxima) e uma cauda de longa extensão (fótons espalhados, que depositam energia a distâncias maiores). A separação entre esses dois regimes é essencial para entender por que algoritmos que ignoram o transporte eletrônico falham — eles capturam a cauda de espalhamento mas erram o pico.
No CCC, o scaling de heterogeneidades é feito ao longo do eixo de cada cone usando a densidade radiológica acumulada. Isso permite contabilizar variações de densidade sem recalcular o kernel inteiro para cada ponto — uma aproximação que funciona surpreendentemente bem na prática. A implementação descrita por Cho (2012) usa tipicamente 24 a 48 cones distribuídos em ângulo sólido, com o modelo de três fontes alimentando o TERMA que entra na convolução.
A validação do CCC contra simulações Monte Carlo (EGS4) e medidas experimentais mostrou concordância típica dentro de 2–3% em meios homogêneos e heterogêneos, mesmo em situações desafiadoras como interfaces tecido-pulmão. O CCC foi implementado com sucesso em vários sistemas de planejamento comerciais — notadamente o Pinnacle (Philips) e o Oncentra (Elekta) — e continua sendo um dos algoritmos mais utilizados na rotina clínica mundialmente. Para um mergulho técnico completo nos kernels de Mackie, no scaling de densidade, na implementação do CCC por Ahnesjö e na validação de Cho, leia nosso artigo dedicado sobre kernels de deposição e collapsed cone convolution.
Pencil Beam e AAA: Os Algoritmos Comerciais Mais Difundidos
O pencil beam é uma forma 2D de superposição: o feixe clínico é decomposto em beamlets infinitesimais, e a dose total é obtida somando as contribuições de cada pencil beam. Conceitualmente mais simples que a convolução 3D completa e computacionalmente mais rápido, foi durante muito tempo o algoritmo dominante em TPS comerciais.
A determinação dos kernels de pencil beam pode ser feita por diferentes vias: medida direta com filmes em profundidade usando campos muito estreitos, convolução analítica com kernels gerados por Monte Carlo, ou integração longitudinal dos kernels pontuais. Cada implementação comercial faz suas próprias escolhas, o que explica por que “pencil beam” pode se referir a algoritmos com desempenhos bastante diferentes.
A grande limitação do pencil beam aparece em meios heterogêneos: o scaling de densidade é feito apenas na direção do feixe (longitudinal). O transporte lateral de elétrons em interfaces de densidade diferente — especialmente na transição tecido mole → pulmão — é mal modelado. Isso leva a superestimação sistemática da dose dentro do pulmão e subestimação na interface. Para feixes de alta energia e campos pequenos, a discrepância pode ultrapassar 10%.
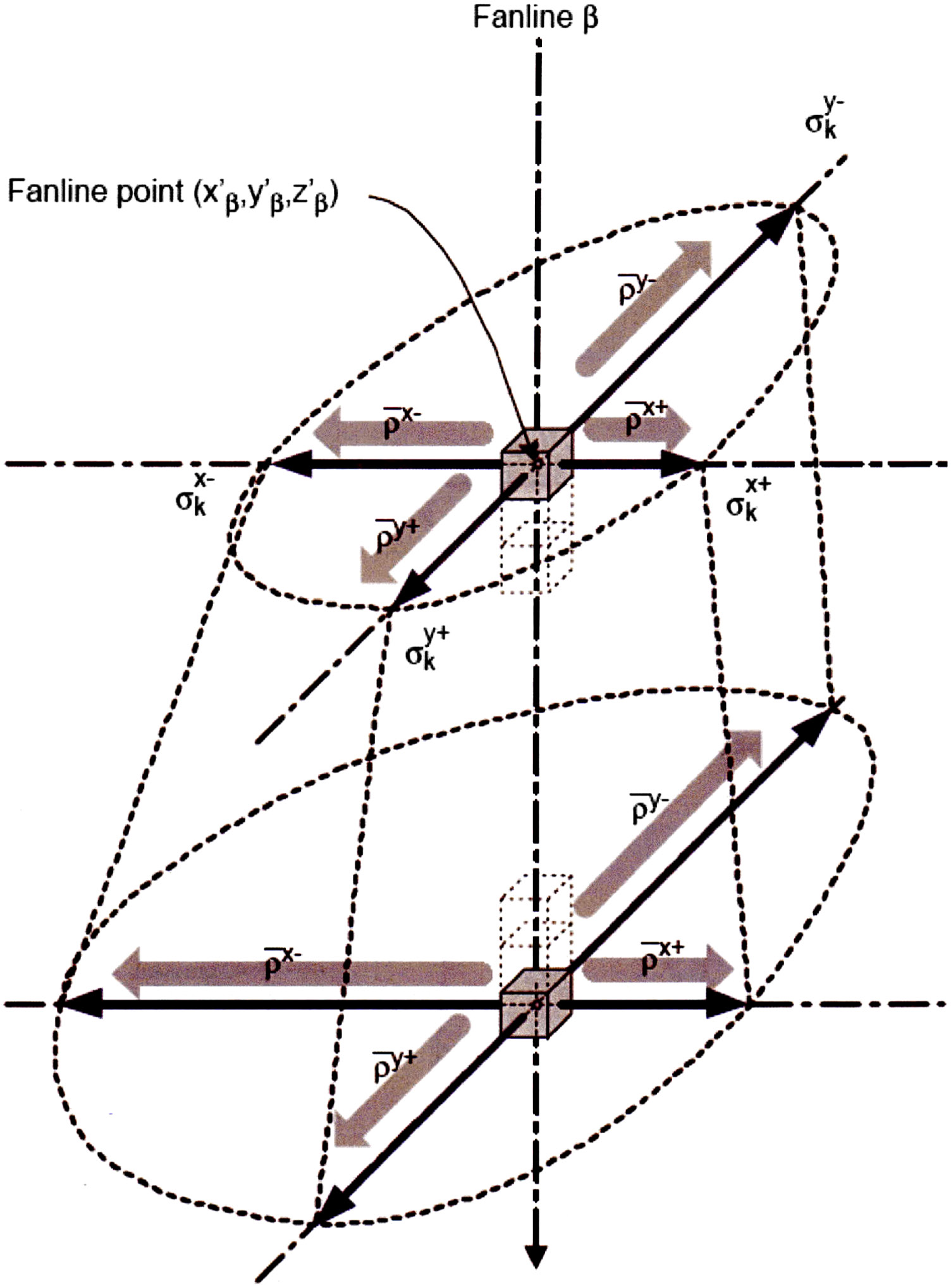
O AAA (Analytical Anisotropic Algorithm), desenvolvido e implementado no Eclipse (Varian) a partir de 2005, foi concebido como evolução do pencil beam convencional. A diferença fundamental: cada beamlet é separado em componentes (fótons primários, espalhamento extrafocal e elétrons contaminantes), e a dose de espalhamento é modelada por convolucões laterais com kernels anisotrópicos que se propagam em seis direções independentes (±x, ±y, ±z), ponderados pela densidade relativa local.
Em meio heterogêneo, as componentes primária e de espalhamento são ponderadas pela densidade relativa local. Comparado ao pencil beam convencional, o AAA modela significativamente melhor o transporte lateral em tecidos de baixa densidade. Porém, o AAA não trata o transporte de elétrons com o mesmo rigor do CCC ou Monte Carlo — ele usa uma aproximação anisotrópica que captura as tendências gerais mas pode ter desvios em geometrias extremas. Para uma análise detalhada com comparações quantitativas em meios heterogêneos, confira nosso artigo sobre pencil beam e AAA.
Monte Carlo e Acuros: A Fronteira do Cálculo de Dose
O Monte Carlo simula cada interação individual de fótons com a matéria, seguindo a cascata de elétrons secundários, fótons espalhados e suas subsequentes interações até que toda a energia seja absorvida ou as partículas escapem do volume de interesse. É a abordagem mais fundamentada fisicamente e serve como referência (benchmark) para validação de todos os outros algoritmos. Não há aproximações na física — apenas incerteza estatística que diminui com o número de histórias simuladas.
Os principais códigos Monte Carlo usados em radioterapia incluem EGS (Electron Gamma Shower — o mais difundido para dosimetria médica), MCNP (Monte Carlo N-Particle — desenvolvido em Los Alamos), GEANT4 (do CERN, cada vez mais usado em física médica) e Penelope (focado em fótons e elétrons de baixa energia). A simulação completa de um LINAC — do alvo de tungstênio até o paciente — exige modelar tanto o cabeçote (filtro aplainador, colimadores, ar) quanto o transporte no paciente.
Historicamente, Monte Carlo era considerado proibitivamente lento para uso clínico de rotina. Nas últimas duas décadas, implementações comerciais como o Monaco (Elekta), soluções baseadas em GPU (como o XVMC) e técnicas de redução de variância reduziram drasticamente o tempo de cálculo. Ainda assim, Monte Carlo continua mais lento que os métodos analíticos para a maioria dos cenários de rotina — um cálculo que leva segundos com pencil beam pode levar minutos com Monte Carlo. Já exploramos as aplicações clínicas do Monte Carlo em profundidade — veja nosso guia completo de Monte Carlo em radioterapia e o artigo sobre Monte Carlo para fótons na clínica.
Uma alternativa determinística ao Monte Carlo que ganhou destaque nos últimos anos é o Acuros XB, implementado no Eclipse (Varian). Em vez de simular partículas individuais aleatoriamente, o Acuros resolve numericamente a equação linear de transporte de Boltzmann (LBTE), discretizando o espaço em voxels, as direções em ângulos sólidos e as energias em grupos. O resultado converge para a mesma solução física que o Monte Carlo, mas com tempo computacional mais previsível e geralmente 5–10x mais rápido que um MC com incerteza comparável.
O Acuros calcula naturalmente dose no tecido ($D_t$), não dose na água — o que é fisicamente mais correto mas exige atenção na comparação com experiência clínica histórica baseada em $D_w$. Para o aprofundamento completo em fundamentos do Monte Carlo, códigos MC, implementações em TPS comerciais, dose por MU, hardware e o futuro do cálculo de dose, leia nosso artigo dedicado sobre Monte Carlo e Acuros no cálculo de dose clínico.
Comparação entre Algoritmos na Prática Clínica
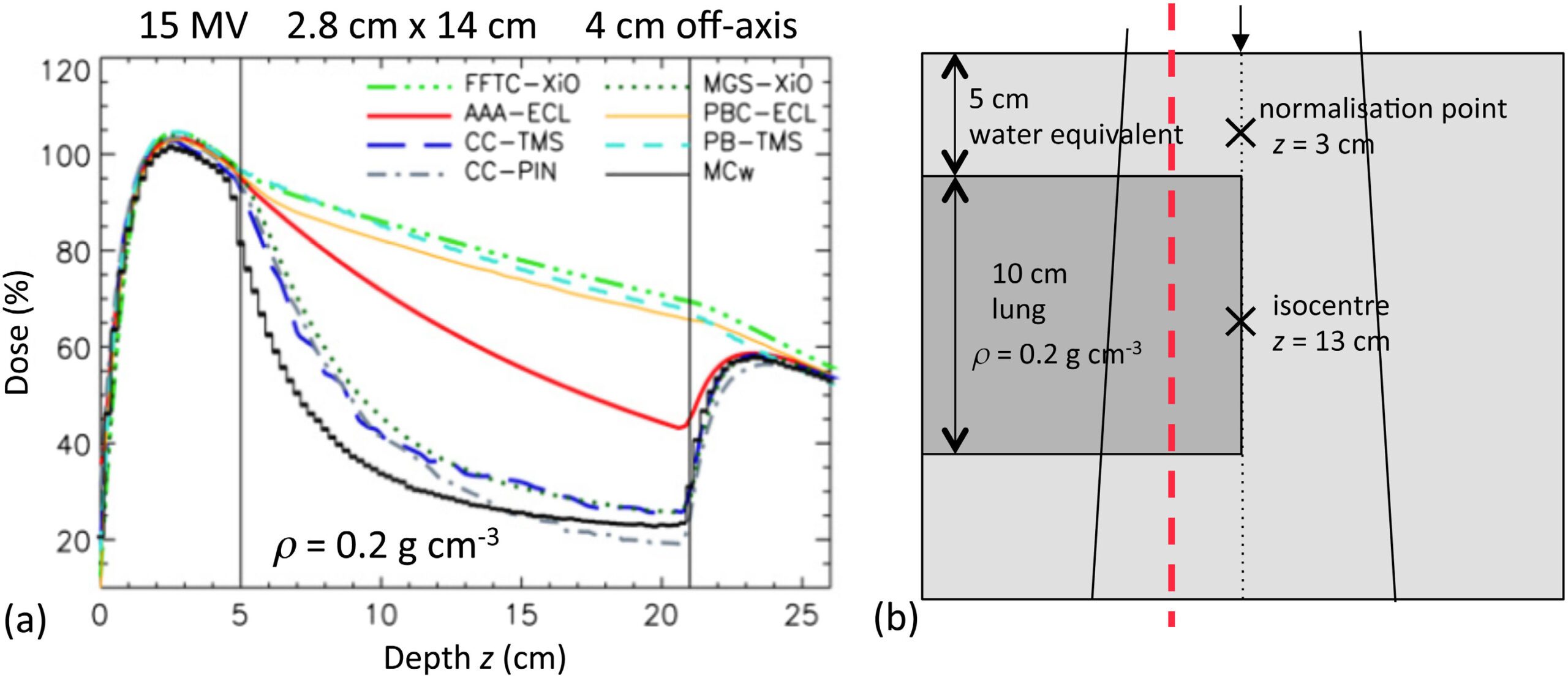
A diferença entre algoritmos se manifesta mais claramente em condições desafiadoras: campos pequenos, feixes de alta energia e heterogeneidades acentuadas — especialmente pulmão. A figura ao lado ilustra isso de forma dramática: para um feixe de 15 MV, campo 2,8×14 cm, 4 cm off-axis, atravessando 10 cm de pulmão (ρ = 0,2 g/cm³), as curvas de dose em profundidade divergem significativamente entre os algoritmos.
Monte Carlo ($MC_w$) serve como referência. O Collapsed Cone (CC-TMS, CC-PIN) acompanha razoavelmente bem, com desvios moderados na interface e dentro do pulmão. O AAA (AAA-ECL) segue de perto o CCC mas com desvios na interface tecido-pulmão. Já o Pencil Beam (PB-TMS, PBC-ECL) superestima a dose dentro do pulmão por uma margem clinicamente significativa e não consegue reproduzir a redução de dose lateral causada pela falta de equilíbrio eletrônico.
Tabela Comparativa dos Algoritmos de Cálculo de Dose
| Característica | Broad-Beam | Clarkson | CCC | Pencil Beam | AAA | Monte Carlo | Acuros |
|---|---|---|---|---|---|---|---|
| Tipo (Knöös) | Tipo a | Tipo a | Tipo b | Tipo a/b* | Tipo b | Tipo b | Tipo b |
| Transporte e⁻ | Não | Não | Sim (scaling) | Parcial | Sim (anisotr.) | Sim (explícito) | Sim (LBTE) |
| Heterogeneidades | Correções 1D | Correções 1D | Scaling 3D | Scaling 1D | Scaling 3D | Explícito | Explícito |
| Precisão em pulmão | Pobre | Limitada | Boa | Pobre | Boa | Referência | Equivalente MC |
| Velocidade relativa | Muito rápido | Rápido | Moderado | Rápido | Moderado | Lento | Moderado-rápido |
| Dose reportada | $D_w$ | $D_w$ | $D_w$ | $D_w$ | $D_w$ | $D_t$ (conv. $D_w$) | $D_t$ ou $D_w$ |
| TPS comercial | Legado | Legado | Pinnacle, Oncentra | Vários | Eclipse | Monaco, XVMC | Eclipse |
*Pencil beam pode ser tipo a ou b dependendo da implementação. Fonte: compilação baseada no Handbook of Radiotherapy Physics: Theory and Practice, 2nd Ed.
Na prática clínica, a escolha do algoritmo deve considerar o sítio anatômico e o cenário clínico. Para planejamentos em abdome, pelve ou cabeça e pescoço — onde as heterogeneidades são menos dramáticas — mesmo um pencil beam pode ser aceitável para planejamento forward, embora um algoritmo tipo “b” seja sempre preferível. Para pulmão, mama com campo tangencial passando por pulmão, mediastino, ou qualquer situação com campos pequenos de alta energia, um algoritmo tipo “b” (CCC, AAA, Monte Carlo ou Acuros) é essencial e não-negociável.
O relatório recente da ASTRO e VA sobre recomendações de DVH reforça a importância de algoritmos precisos: as restrições de dose a órgãos de risco só fazem sentido se o cálculo de dose for confiável nos cenários em que esses órgãos se encontram. Usar um pencil beam para estabelecer constraints de pulmão em SBRT é um exercício de ilusão.
Perspectivas e o Futuro do Cálculo de Dose
A tendência dos últimos 20 anos é inequívoca: os algoritmos baseados em transporte explícito de partículas — Monte Carlo e soluções determinísticas como o Acuros — estão se tornando o padrão para verificação final de planos de tratamento. O aumento de potência computacional, especialmente com GPUs dedicadas, está tornando o Monte Carlo viável também como engine de otimização inversa, não apenas como ferramenta de verificação pós-otimização.
O debate dose na água versus dose no tecido tende a se resolver na direção do tecido, à medida que os algoritmos baseados em transporte se tornam dominantes. A comunidade de física médica precisará recalibrar parte de sua experiência clínica acumulada, especialmente para estruturas ósseas e tecido adiposo, onde a diferença é relevante.
Independentemente do algoritmo escolhido, um princípio fundamental permanece inalterado: o resultado do cálculo só é tão bom quanto os dados de entrada. Commissioning do feixe inadequado, CT com artefatos, ou tuning empírico mal feito invalidam qualquer sofisticação algorítmica. Conforme enfatizado na seção 47.5 do Handbook, a validação contra medidas experimentais é insubstituível — e a precisão de um modelo simples bem calibrado pode superar a de um modelo sofisticado mal configurado.
Este guia percorreu a jornada completa dos algoritmos de cálculo de dose por fótons em radioterapia. Para aprofundar cada tópico com equações, derivações e exemplos detalhados, explore os artigos desta série: métodos empíricos broad-beam, superposição, Clarkson e TERMA, kernels de deposição e collapsed cone convolution, pencil beam e AAA e Monte Carlo e Acuros no cálculo de dose clínico.
